DeepMind团队于2026年3月18日公开了名为"大规模高效探索"的最新研究成果,推出一种旨在显著提高数据利用率的在线学习算法。该算法针对大语言模型在通过人类反馈进行强化学习(RLHF)时面临的数据饥渴难题,通过引入主动探索机制,实现了在同等性能表现下对人类标注数据需求的急剧下降。

Efficient Exploration at Scale
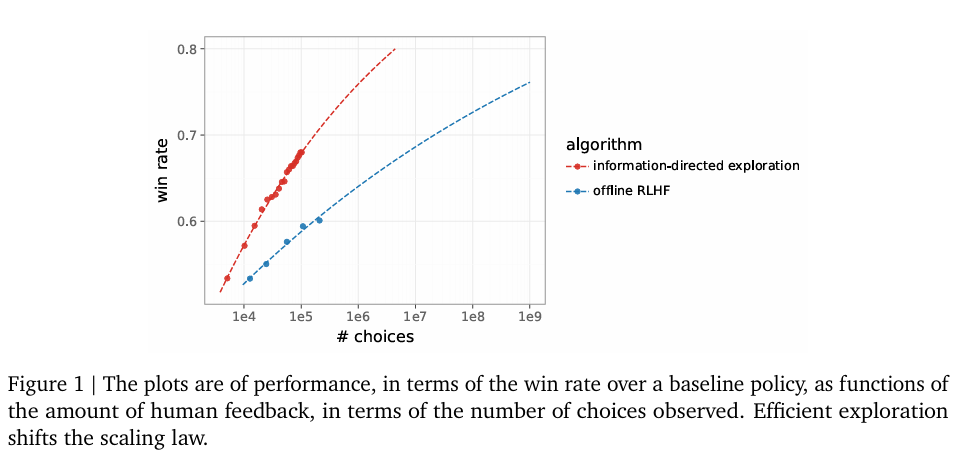
We develop an online learning algorithm that dramatically improves the data efficiency of reinforcement learning from human feedback (RLHF). Our algorithm incrementally updates reward and language models as choice data is received. The reward model…

此外,该研究还通过引入一种被称为"肯定式微推"的机制,解决了在线强化学习中常见的性能崩溃问题,确保了模型更新过程中的稳定性。这项技术的突破意味着智能体在通往人工智能安全与超级智能的道路上,能够以更低的人力成本更精准地捕捉并对齐人类价值观。