如图,我使用的是gpt-team,今天中午我感觉额度使用明显变快了于是看了一眼CPA后台,突然发现单次输入达到了500多K,于是去codex看了一下,显示上下文有950K
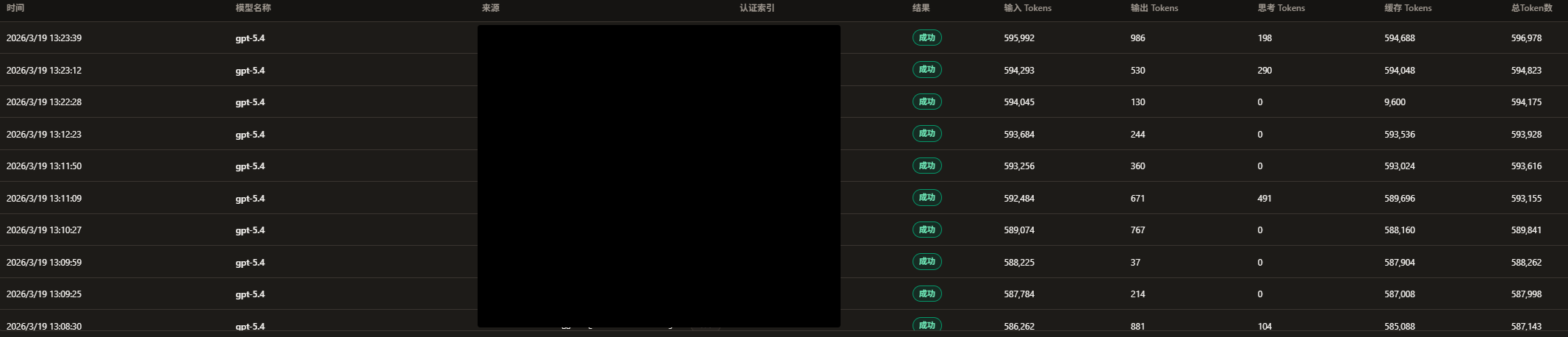
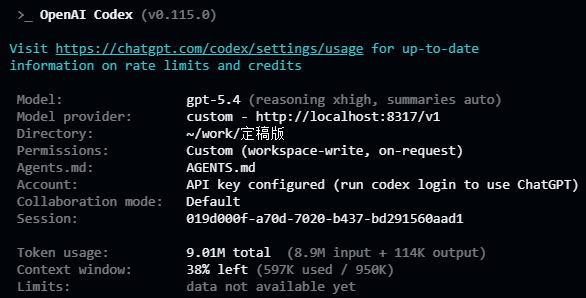
如图,我使用的是gpt-team,今天中午我感觉额度使用明显变快了于是看了一眼CPA后台,突然发现单次输入达到了500多K,于是去codex看了一下,显示上下文有950K
依旧前沿慢讯 出的时候就是1m的模型
1M的吧
一直有呀
怎么切换成这么大的捏,我也是gpt-team,还是 258k

多了会胡言乱语。默认就行
记得说超过300k就会有很大的幻觉啊
原来是这样吗,我之前好像一直都是原来GPT-5.2一样的上下文,今天突然感觉上下文变大了
我之前在别的评论区看到有人说实测下来后面超出的部分会二倍消耗token,老实了
不建议开 效果一般 不如压缩 开了还是2x消耗
我都是开450k,1m感觉有点鸡肋,400k之后是2x,所以我是450k,到400k压缩
好的好的,谢谢大佬的建议,我就说今天这么消耗有点快
慢慢慢讯
是1M的啊
模型理论上限是1050k(1k=1000算的话)
不过这个特性前几个版本需要手动设置上下文窗口大小后开启
难道新版本默认开启了(我还没去核查)